- 测试题一
- 1.写一个空间复杂度为 O(1)的快速排序
- 2.1删除链表的第 k 个节点
- 2.2.删除链表的倒数第 k 个节点
- 3.1手写 Function.prototype.bind
- 3.2手写 Function.prototype.call
- 3.3手写 Function.prototype.apply
- 4.手写 instanceof(a, b)
- 5.实现大数相加:
- 6.解释浏览器缓存
- 7.网络分层,知道多少?
- 7.1 HTTP 与 HTTPS
- 什么是 HTTP
- 什么是 HTTPS
- 为什么要使用 HTTPS
- HTTPS 是如何加密的——TLS/SSL协议
- 什么是CA
- HTTP 和 HTTPS 连接是如何建立
- 8.跨域的方案
- document.domain + iframe (只有在主域相同的时候才能使用该方法)
- nginx反向代理
- 9.解释简单请求和非简单请求? 跨域如何带上cookie?
- 10.React 事件系统理解
- 11.React事件阻止冒泡
- 12. React.useEffect 和 useLayoutEffect 的执行顺序
- 12.1useEffect 和 useLayoutEffect 的区别?
- 12.2 对于 useEffect 和 useLayoutEffect 哪一个与 componentDidMount,componentDidUpdate 的是等价的?
- 12.3 useEffect 和 useLayoutEffect 哪一个与 componentWillUnmount 的是等价的?
- 12.4 为什么建议将修改 DOM 的操作里放到 useLayoutEffect 里,而不是 useEffect?
- 13.解释箭头函数 和 this 指向
- 14、不重复数
- 给定一个id数组和数字m,从数组中取出m个id,求剩余最小不重复id的个数。
- 15.排序问题
- 测试题二
- 1.http 301 302 307 的区别
- 2.301 和 302 哪个对 seo 更友好(301)
- 3.跨域是什么、如何解决
- 4.jsonp 有什么缺点
- 5.base64和外链的应用场景,各自的优缺点
- 6.http缓存机制
- 7.https 的握手过程
- 8.Set/Map 、weakSet/weakMap的区别
- 9.hook 的局限性
- 10.setState 和 hook 的区别
- 11.decorator 的作用,编译后是什么样子的
- 12.Symbol 是什么,一般用来做什么
- 模拟私有属性
- 13.csrf 是什么,如何防范
- 14.sql注入是什么,如何防范
- 15.react 调用 setState 之后发生什么
- 16.nodejs 事件循环机制
- 17.pm2原理,有哪些模式(cluster fork)
- 18.docker 和 k8s 有了解多少
- 19. 移动端一个元素的拖动,如何实现和优化(节流,改变位置)
- 20. for in / for of
- 21.描述链表的反转如何实现,复杂度多少
- 22.实现 instanceof
- 23.实现一个对象被 for of 遍历
- 24.实现链表的添加、删除。复杂度是多少
- 25.给两段效果上都可以实现继承的代码,说出差异
- 26.this 输出问题
- 27.如何监听 html 外链资源加载失败?
- 28.Mutation Observer、IntersectionObserver 使用场景
- 29. 127.0.0.1 和 0.0.0.0 差别(一个只能通过 localhost ,另一个可以通过本机 ip 或者 localhost 都可以)
- 30.利用 Promise js sleep 函数实现
- 31.jsx 转换后是什么样子的
- 32.redux compose 函数是做什么的,中间件呢
- 33.redux-sage 是什么,和 redux-thunk 有什么区别
- 34.dva 了解吗
- 35.umi.js 有用过吗?
- 36.req.pipe(res)
- 37.stream 如何处理数据消费和数据生产的速率不一致问题
- 38.writeable stream drain 事件是做什么的?
- 测试题三
- 1.JS继承
- 1.2 原型链继承
- 1.3 构造函数继承(call)
- 1.4 组合继承
- 1.5 原型式继承(Object.create)
- 1.6 寄生式继承
- 1.7 组合寄生式继承(最佳)
- 1.8 ES6 Extends继承
- 2.实例属性和原型属性的区别
- 4.instanceof 的原理
- 5.浏览器缓存刷新
- 6.缓存位置
- 7.Service Worker
- 8.Push Cache 的具体处理方式
- 9.HTTP2 和HTTP3的优缺点
- 10.HTTP2 有没有可能比 HTTP1 还要更慢
- 11.var、let、const 的区别
- 12.说出打印结果
- 13.webpack常用plugins和loader
- 13.1 何为插件(Plugin)
- 13.2 何为loader
- 14.如果有一个工程打包特别大,如何进行优化?
- 15.用户信息存储的方式Cookie、Session、Token
- 16.React 性能优化的方式
- 17. 实现一个防抖函数
- 17.1 实现一个节流函数
- 18.说出以下代码的输出
- 19. let a = "abc",解释器在解释在这句话的过程中,内存发生的变化,比如内存放在哪里,申请了多大的内存
- 20.介绍一下 esm 和 cjs 的差异
- 21.介绍一下前端安全问题
- 22.假设有一个页面需要实现下拉无限滚动加载,如何实现和优化
- 23.实现如下这样的函数(函数柯里化)
🌙 测试题一
🌙 1.写一个空间复杂度为 O(1)的快速排序
// 非原地排序算法 Time O(nlog(n)) Space O(n)
function quickSort(arr) {
if (arr.length < 2) return arr;
let pivot = arr.pop();
let left = [], right = [];
for (let i = 0; i < arr.length; i++) {
if (arr[i] < pivot) {
left.push(arr[i])
} else {
right.push(arr[i])
}
}
return [...quickSort(left), pivot, ...quickSort(right)]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// 原地排序算法 Time O(nlog(n)) Space O(1)
function quickSort(arr) {
function sort(arr, left, right) {
if (left >= right) return;
// 一次快排
// const index = partition1(arr, left, right);
// const index = partition2(arr, left, right);
// 切分 [left, right] = [left, index - 1] + [index] + [index + 1, right]
// sort(arr, left, index - 1); // 将左半部分arr[left .. index-1]排序
// sort(arr, index + 1, right); // 将左半部分arr[index+1.. right]排序
// 三路快排
const {lt, gt} = partition3(arr, left, right);
sort(arr, left, lt - 1);
sort(arr, gt + 1, right);
}
/**
* 排序关键:切分
* 1.对于某个 index,arr[index] 已经排定;
* 2.arr[left] 到 arr[index-1] 中的所有元素都不大于 arr[index];
* 3.arr[index+1] 到 arr[right] 中的所有元素都不小于 arr[index]。
* */
// 1.左右双指针法
function partition1(arr, begin, end) {
// 基准数据
let pivot = arr[end];
let left = begin;
let right = end;
while (left < right) {
// 从前向后扫描,直到找到一个大于pivot的值
while (left < right && arr[left] <= pivot) {
left++;
}
// 从后往前扫描,直到找到一个小于pivot的值
while (left < right && arr[right] >= pivot) {
right--;
}
// 然后交换
if (left < right) {
[arr[left], arr[right]] = [arr[right], arr[left]]
}
}
// 此时left >= right,一趟快速排序完成,这时将arr[end]和array[left]的值进行一次交换。
[arr[left], arr[end]] = [arr[end], arr[left]]
return left;
}
// 2.挖坑法
function partition2(arr, begin, end) {
let pivot = arr[end];
let left = begin;
let right = end;
while (left < right) {
while (left < right && arr[left] <= pivot) {
left++
}
arr[right] = arr[left];
while (left < right && arr[right] >= pivot) {
right--
}
arr[left] = arr[right];
}
arr[right] = pivot;
return right;
}
// 3.三路快排
function partition3(arr, begin, end) {
let pivot = arr[begin];
let lt = begin;
let i = begin + 1;
let gt = end;
while (i <= gt) {
if (arr[i] < pivot) {
[arr[i], arr[lt]] = [arr[lt], arr[i]];
i++;
lt++;
} else if (arr[i] > pivot) {
[arr[i], arr[gt]] = [arr[gt], arr[i]];
gt--;
} else {
i++;
}
}
// 现在 arr[left..lt-1] < pivot = arr[lt..gt] < arr[gt+1..right]成立
return {lt, gt}
}
sort(arr, 0, arr.length - 1)
return arr;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
🌙 2.1删除链表的第 k 个节点
function ListNode(val) {
this.val = val;
this.next = null;
}
function removeKthNodeFromStart(root, k) {
if (!root || k <= 0) return root;
if (k === 1) {
return root.next
}
// 处理 K >= 2
// 获取链表长度
let len = 1;
let head = root;
while (head.next) {
head = head.next;
len++;
}
// k比len大
if (k > len) {
return root;
}
// k <= len
let cur = root;
while (k > 2) {
cur = cur.next;
k--;
}
cur.next = cur.next.next;
return root;
}
function generateLinkedListFromArr(arr) {
let pre = new ListNode();
let node = pre;
for (let n of arr) {
node.next = new ListNode(n);
node = node.next;
}
this.root = pre.next;
return pre.next;
}
function printNodeList(root) {
let str = '';
let cur = root;
while (cur) {
str += cur.val + '>';
cur = cur.next;
}
return str;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
🌙 2.2.删除链表的倒数第 k 个节点
/**
* @param {ListNode} head
* @param {number} n
* @return {ListNode}
*/
var removeNthFromEnd = function (head, n) {
let dummy = new ListNode();
dummy.next = head;
let slow = dummy;
let fast = dummy;
while (n > 0) {
fast = fast.next;
n--;
}
while (fast && fast.next) {
fast = fast.next;
slow = slow.next;
}
slow.next = slow.next.next;
return dummy.next;
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
🌙 3.1手写 Function.prototype.bind
Function.prototype._bind = function (context, ...args) {
let that = this;
return function (..._args) {
// return that.apply(context, [...args, ..._args])
return that.call(context, ...args, ..._args)
}
}
2
3
4
5
6
7
🌙 3.2手写 Function.prototype.call
Function.prototype._call = function (context, ...args) {
context = context || window;
let fn = Symbol('fn');
context[fn] = this;
let result = context[fn](...args);
// Reflect.deleteProperty(context, fn);
delete context[fn]
return result;
}
2
3
4
5
6
7
8
9
10
🌙 3.3手写 Function.prototype.apply
Function.prototype._apply = function (context, ...args) {
context = context || window;
let fn = Symbol('fn');
context[fn] = this;
const result = context[fn](args);
delete context[fn];
return result;
}
2
3
4
5
6
7
8
9
10
🌙 4.手写 instanceof(a, b)
instanceof 运算符用于测试构造函数的 prototype 属性是否出现在对象原型链中的任何位置
首先 instanceof 左侧必须是对象, 才能找到它的原型链
instanceof 右侧必须是函数, 函数才会有prototype属性
迭代 , 左侧对象的原型不等于右侧的 prototype时, 沿着原型链重新赋值左侧
function _instanceof(left, right) {
if (!left || !right) return false;
let R = right.prototype;
while (true) {
if (left === null) {
return false;
} else if (left.__proto__ === R) {
return true;
} else {
left = left.__proto__
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
🌙 5.实现大数相加:
add('294732947329847328947328947382', '11') // 返回'294732947329847328947328947393'
function add(a, b) {
let lena = a.trim().length;
let lenb = b.trim().length;
if (!lena || !lenb) return a.trim() || b.trim();
let max = lena > lenb ? lena : lenb;
a = a.trim().padStart(max, 0);
b = b.trim().padStart(max, 0);
let ans = '';
let sum = 0;
let carry = 0;
// 从右往左
for(let i=max-1; i>=0; i--) {
sum = (+a[i]) + (+b[i]) + carry;
if(sum >= 10) {
carry = ~~(sum/10);
sum = sum % 10;
}
ans = sum + ans;
sum = 0;
}
if(carry) {
ans = carry + ans;
}
return ans;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
🌙 6.解释浏览器缓存
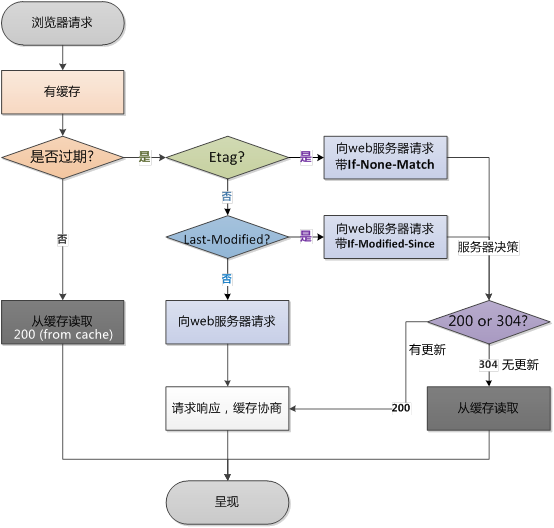
缓存位置:
Memory Cache 内存缓存,效率最快
Disk Cache 磁盘缓存
Push Cache 推送缓存(HTTP/2)
Service Worker Cache Service Worker 借鉴了 Web Worker的 思路,即让 JS 运行在主线程之外,由于它脱离了浏览器的窗体,因此无法直接访问
DOM。虽然如此,但它仍然能帮助我们完成很多有用的功能,比如离线缓存、消息推送和网络代理等功能。其中的离线缓存就是 Service Worker Cache。
Service Worker 同时也是 PWA 的重要实现机制
缓存机制
1.强缓存
expires: http1.0 关键字
Expires = 时间,HTTP 1.0 版本,缓存的载止时间,允许客户端在这个时间之前不去检查(发请求),Expires 的一个缺点就是,返回的到期时间是服务器端的时间,这样存在一个问题,如果客户端的时间与服务器的时间相差很大,那么误差就很大,所以在HTTP 1.1版开始,使用Cache-Control: max-age=秒替代。
cache-control: http1.1关键字(优先级更高)
- public:表明其他用户也可以利用缓存。(允许代理服务器)
- private:表明缓存服务器只对特定用户提供资源缓存的服务,对于其他的用户,缓存服务器不会做出响应。(不允许代理服务器)
- no-cache:表明不缓存过期资源,其实是为了防止拿到过期的资源,进入协商缓存。
- no-store:暗示请求或响应中包含机密信息,是真正的禁用缓存。
- max-age:max-age = 秒,HTTP 1.1版本,资源在本地缓存多少秒。
如果max-age和Expires同时存在,Cache-Control的max-age优先。
2.协商缓存
last-modified: http1.0, 值为GMT时间, 和 if-modified-since 配合使用
当第一次请求资源时,源服务器响应后返回last-modified值和响应内容,客户端会将响应内容和last-modified一起缓存在本地,第二次请求时会将请求体连同if-modified-since(等于last-modified的值)一起发送给服务端,服务端会根据if-modified-since判定资源是否改变,如果没有改变会响应304返回一个空的响应体,如果资源改变返回新的内容。
etag: http1.1, 值为文件的hash值,和 if-none-match 配合使用
根据实体内容生成一段hash字符串,标识资源的状态,由服务端产生,资源改变这个值就会改变个人感觉类似于资源的一种抽象映射。请求过程类似于last-modified,不过它作为if-none-match(服务端响应的etag)发送给服务端判断这个值是否与服务端的etag一致看资源是否改变。
为什么有了last-modified还要有etag?
某些服务器不能精确得到资源的最后修改时间,这样就无法通过最后修改时间判断资源是否更新
如果资源修改非常频繁,在秒以下的时间内进行修改,而Last-modified只能精确到秒
一些资源的最后修改时间改变了,但是内容没改变,使用ETag就认为资源还是没有修改的
🌙 7.网络分层,知道多少?
- OSI七层网络协议:
| OSI层 | 功能 | 设备 | 协议 |
|---|---|---|---|
| 应用层 | 用户接口、应用程序、电子邮件、文件服务、虚拟终端 | 网关 | TFTP、HTTP、SNMP、FTP、SMTP、DNS、Telnet |
| 表示层 | 数据的表示、压缩和加密(数据格式化、代码转换、数据加密) | 网关 | 无 |
| 会话层 | 绘画的建立和结束(解除或建立与别的节点的联系) | 网关 | 无 |
| 传输层 | 提供端对端的接口 | 网关 | TCP、UDP |
| 网络层 | 微数据包选择路由,寻址 | 路由器 | IP、ICMP、RIP、OSPF、BGP、IGMP |
| 数据链路层 | 保证无差错的数据链路,传输有地址的帧以及错误的检测功能 | 交换机、网桥、网卡 | SLIP、CSLIP、PPP、ARP、RARP、MTU |
| 物理层 | 传输比特流,以二进制数据形式在物理媒体上传输数据 | 集线路、中继器 | IS02110、IEEE802、IEEE802.2 |
- TCP/IP层次模型共分为四层:应用层->传输层->网络层->数据链路层
TCP/IP协议与低层的数据链路层和物理层无关
| TCIP/IP层 | 协议 |
|---|---|
| 应用层 | TFTP、HTTP、SNMP、FTP、SMTP、DNS、Telnet |
| 传输层 | TCP、UDP |
| 网络层 | IP、ICMP、RIP、OSPF、BGP、IGMP |
| 数据链路层 | SLIP、CSLIP、PPP、ARP、RARP、MTU· |
- 为什么需要三次握手呢?
为了防止已失效的连接请求报文段突然又传送到了服务端,因而产生错误。
🌙 7.1 HTTP 与 HTTPS
🌙 什么是 HTTP
HTTP 指的是超文本传输协议(HyperText Transfer Protocol),它的特点:
- 无状态:协议对客户端没有状态存储,对事物处理没有“记忆”能力,比如访问一个网站需要反复进行登录操作
- 无连接:HTTP/1.1之前,由于无状态特点,每次请求需要通过TCP三次握手四次挥手,和服务器重新建立连接。比如某个客户机在短时间多次请求同一个资源,服务器并不能区别是否已经响应过用户的请求,所以每次需要重新响应请求,需要耗费不必要的时间和流量
- 基于请求和响应:基本的特性,由客户端发起请求,服务端响应
- 简单快速、灵活
- 通信使用明文、请求和响应不会对通信方进行确认、无法保护数据的完整性
| 版本 | 产生时间 | 内容 | 发展现状 |
|---|---|---|---|
| HTTP/0.9 | 1991年 | 不涉及数据包传输,规定客户端和服务器之间通信格式,只能GET请求 | 没有作为正式的标准 |
| HTTP/1.0 | 1996年 | 传输内容格式不限制,增加PUT、PATCH、HEAD、 OPTIONS、DELETE命令 | 正式作为标准 |
| HTTP/1.1 | 1997年 | 持久连接(长连接)、节约带宽、HOST域、管道机制、分块传输编码 | 2015年前使用最广泛 |
| HTTP/2 | 2015年 | 多路复用、服务器推送、头信息压缩、二进制协议等 | 逐渐覆盖市场 |
🌙 什么是 HTTPS
HTTPS 指的是超文本传输安全协议(Hypertext Transfer Protocol Secure),HTTPS 就是将 HTTP 中的传输内容进行了加密,然后通过可靠的连接,传输到对方的机器上。加密的协议是 TLS,其前身是 SSL。
🌙 为什么要使用 HTTPS
因为 HTTP 是明文传输的,在传输过程中,在一些路由节点中很容易被别人捕获,识别你的内容,再在传输的数据中添加一些其他数据(如广告)。HTTPS 能很有效的解决这个现象,通过加密传输即便在路由节点被第三方捕获,它没有密码,看到的也是一堆乱码,HTTPS 更多的是为安全考虑。
🌙 HTTPS 是如何加密的——TLS/SSL协议
在 TLS/SSL 中,主要实现的就是加密的过程。加密过程中用到了「非对称加密」和「对称加密」俩种加密方式。
对称加密思路比较简单,就是大家约定一个密码进行加密,然后用同一个密码在进行解密,逻辑比较简单。(对称加密密简单高效,性能高,不安全)
非对称加密方法一开始会生成一对密钥,也就是俩个密码。就是说这个加密解密过程会用俩个密钥来完成。如果你用第一把钥匙加密,那么你只能用第二把钥匙才能解开。你用第二把钥匙加密,只能用第一把钥匙解开,这是非对称加密的表现。(如RSA加密算法)(非对称加密安全,性能低)
TLS/SSL结合非对称加密安全和对称加密密简单高效的优点,先使用非对称加密算法将某一密文加密,之后的所有数据采用该密文进行对称加密。这样,既保证了性能,又保证了安全性。
- https网站浏览时的加解密具体过程
在采用非对称加密算法生成俩个钥匙之后,网站需要公布出去其中一把钥匙,我们把公布出去的密码称之为公钥,自己留着的那一把钥匙称之为私钥。我们向全世界广播我们网站公钥是什么,大家都可以通过这个公钥对要传输的数据进行加密,然后我们网站内部会有一个私钥,可以通过私钥解密公钥加密的数据。
怎么将公钥交给你呢
就是浏览器和服务器建立起了连接之后,浏览器会先发送一个信息,就是自己的公钥(公开的密码),然后浏览器拿到这个密码对数据进行加密,加密之后传输给服务器,服务器收到密文之后用自己的私钥解密数据,获得真实数据,完成了加密传输的想法。
这种方式,但也有安全风险,因为在传输公钥的过程中,第三方截取了公钥,然后随便给你发一个密码,你会以为这个密码就是服务器发来的,服务器也不知道密码被截获了。于是就有的CA证书。
🌙 什么是CA
数字证书认证机构(Certificate Authority,缩写为CA)。
服务器不能将非对称加密产生的公钥直接告诉你,因为中间人可能截获这个公钥进行解密篡改,加密,传输。所以想一个下下策了,成立一个官方组织,由它来作认定。
服务器会将产生的公钥交给CA,让他进行登记,他登记后会给我发一个证书,来证明我是我。证书中含有我的公钥内容,还包含一些其他信息,比如我是哪个公司的,域名是什么,谁给我的这个证书等等。
证书中含有我的公钥内容,还包含一些其他信息,比如我是哪个公司的,域名是什么,谁给我的这个证书等等。本来我应该给你公钥的,现在变了,我给你发送一个我的证书,你拿着这个证书去找 CA 质问,这个证书是真的吗,CA 会匹配公钥和证书内的其他信息,看是否真的在他那儿注册过了,如果确认是真的,那就说明证书没被中间人篡改,那你就可以大胆的用证书中的公钥进行加密。当然,数字证书也可能被第三方截获,第三方也得到公钥信息,也可以解密服务器传来的信息,那么,我们让浏览器先设置对称加密的密码的,将密码用公钥加密,传输给服务器,第三方只有公钥,解不开密码,而服务器可以解开,之后就可以通过对称加密的方式进行通讯了,我们就可以安全的传输数据了,再也不怕中间人偷窥了。一般浏览器在操作系统中内置的一些顶级 CA 信息来验证对方证书的真实性,如果证书有问题,浏览器会发出提示。
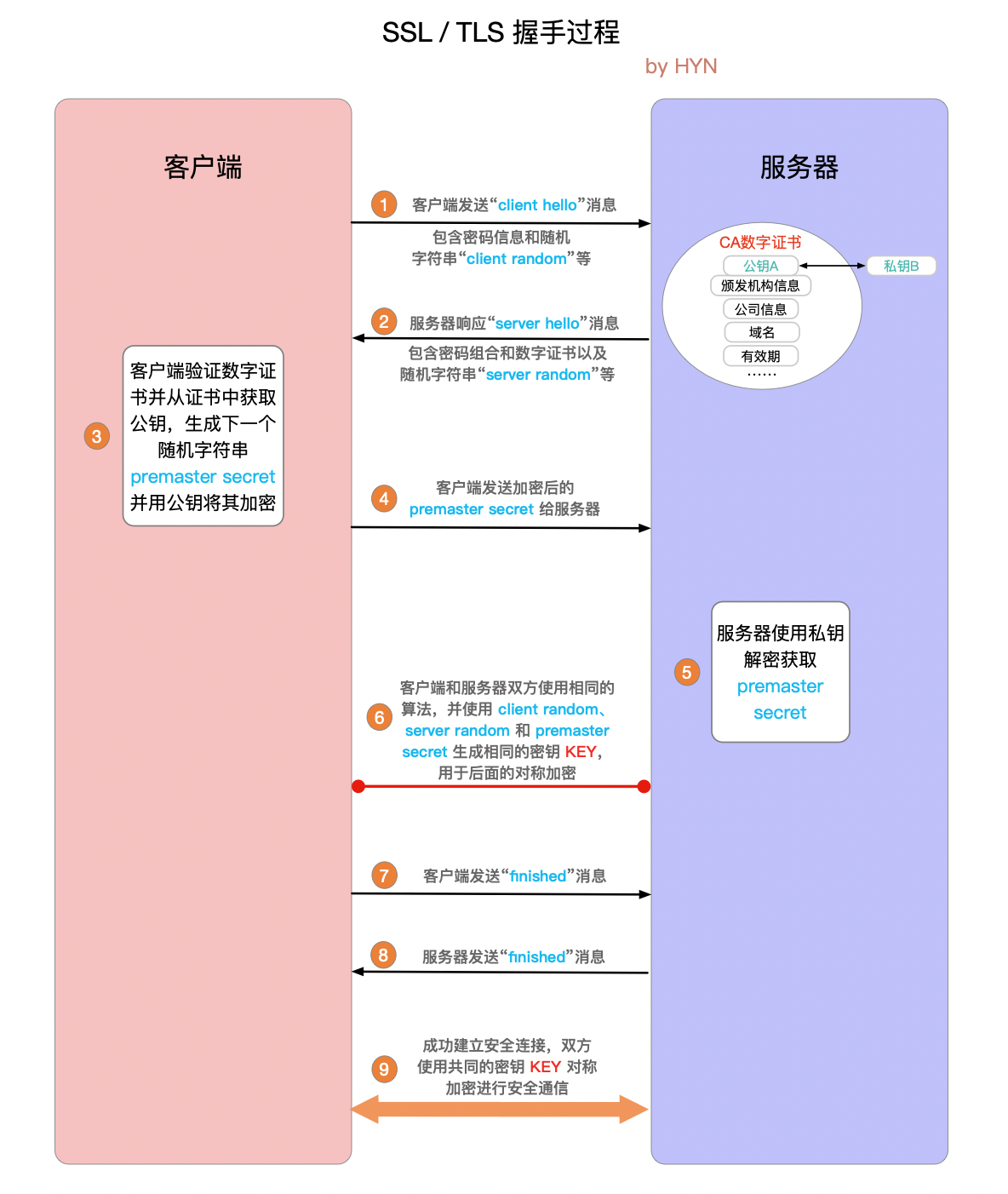
🌙 HTTP 和 HTTPS 连接是如何建立
HTTP 在传输层之上,是依靠于 TCP 连接的。也就是说先建立起 TCP 连接,建立好连接之后双方之间才能传输数据。
HTTP: DNS寻址 ---- 获取IP --- TCP三次握手建立连接 --- HTTP数据 --- TCP四次挥手断开连接
HTTPS: DNS寻址 ---- 获取IP --- TCP三次握手建立连接 --- 建立TLS连接 --- HTTP数据 --- TCP四次挥手断开连接
建立TLS连接过程:
SSL:(Secure Socket Layer,安全套接字层),位于可靠的面向连接的网络层协议和应用层协议之间的一种协议层。SSL通过互相认证、使用数字签名确保完整性、使用加密确保私密性,以实现客户端和服务器之间的安全通讯。该协议由两层组成:SSL记录协议和SSL握手协议。
TLS:(Transport Layer Security,传输层安全协议),用于两个应用程序之间提供保密性和数据完整性。该协议由两层组成:TLS记录协议和TLS握手协议。
客户端发出hello包 (包含支持的加密协议列表)--- 服务器响应hello包(包含服务器选择的加密算法以及数字证书,数字证书里面有公钥)--- 客户端校验证书合法性(向CA机构咨询)--- 检验成功,客户端获取公钥 ---- 客户端告知服务器马上发送加密的消息 --- 客户端使用公钥加密会话密钥key-- TLS建立Finished --- 之后客户端和服务器通过会话秘钥进行对称加密通信(数据传输都使用该对称密钥key进行加密)

🌙 8.跨域的方案
由于浏览器的同源(协议、域名、端口)策略,只有在同源的情况下,才允许访问相同的cookie、localStorage或是发送Ajax请求等。
🌙 document.domain + iframe (只有在主域相同的时候才能使用该方法)
- 在www.a.com/a.html中:
document.domain = 'a.com'; var ifr = document.createElement('iframe'); ifr.src = 'http://www.script.a.com/b.html'; ifr.display = none; document.body.appendChild(ifr); ifr.onload = function(){ var doc = ifr.contentDocument || ifr.contentWindow.document; //在这里操作doc,也就是b.html ifr.onload = null; };1
2
3
4
5
6
7
8
9
10- 在www.script.a.com/b.html中:
document.domain = 'a.com';1JSONP:
SONP是JSON with Padding的略称, 利用script标签不受同源策略的限制
function jsonp({url, params, callback}) { return new Promise((resolve, reject) => { let script = document.createElement('script'); whidow[callback] = function(data) { resolve(data); document.body.removeChild(script); } params = {...params, callback} // wd=hello&callback=search let arr = []; for(let key in params) { arr.push(`${key}=${params[key]}`) } script.src = `${url}?${arr.join('&')}`; document.body.appendChild(script); }) } // 使用 jsonp({ url: 'http://localhost:8080/serach', params: {wd: 'hello'}, callback: 'search' }).then(res => { console.log(res) })1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29postMessage
postMessage是HTML5 XMLHttpRequest Level 2中的API,且是为数不多可以跨域操作的window属性之一,它可用于解决以下方面的问题:
- 页面和其打开的新窗口的数据传递
- 多窗口之间消息传递
- 页面与嵌套的iframe消息传递
- 上面三个场景的跨域数据传递
postMessage()方法允许来自不同源的脚本采用异步方式进行有限的通信,可以实现跨文本档、多窗口、跨域消息传递。
otherWindow.postMessage(message, targetOrigin, [transfer]);1CORS
CORS 需要浏览器和后端同时支持。IE 8 和 9 需要通过 XDomainRequest 来实现。
浏览器会自动进行 CORS 通信,实现 CORS 通信的关键是后端。只要后端实现了 CORS,就实现了跨域。
服务端设置 Access-Control-Allow-Origin 就可以开启 CORS。 该属性表示哪些域名可以访问资源,如果设置通配符则表示所有网站都可以访问资源。
虽然设置 CORS 和前端没什么关系,但是通过这种方式解决跨域问题的话,会在发送请求时出现两种情况,分别为简单请求和复杂请求。
websocket
Websocket是HTML5的一个持久化的协议,它实现了浏览器与服务器的全双工通信,同时也是跨域的一种解决方案。WebSocket和HTTP都是应用层协议,都基于 TCP 协议。但是 WebSocket 是一种双向通信协议,在建立连接之后,WebSocket 的 server 与 client 都能主动向对方发送或接收数据。同时,WebSocket 在建立连接时需要借助 HTTP 协议,连接建立好了之后 client 与 server 之间的双向通信就与 HTTP 无关了。
原生WebSocket API使用起来不太方便,我们使用
Socket.io,它很好地封装了webSocket接口,提供了更简单、灵活的接口,也对不支持webSocket的浏览器提供了向下兼容。<script> let socket = new WebSocket('ws://localhost:3000'); socket.onopen = function () { socket.send('hello');//向服务器发送数据 } socket.onmessage = function (e) { console.log(e.data);//接收服务器返回的数据 } </script>1
2
3
4
5
6
7
8
9
10// server.js let express = require('express'); let app = express(); let WebSocket = require('ws');//记得安装ws let wss = new WebSocket.Server({port:3000}); wss.on('connection',function(ws) { ws.on('message', function (data) { console.log(data); ws.send('world') }); })1
2
3
4
5
6
7
8
9
10
11nodejs中间件代码(使用两次跨域)
实现原理:同源策略是浏览器需要遵循的标准,而如果是服务器向服务器请求就无需遵循同源策略。 代理服务器,需要做以下几个步骤:
- 接受客户端请求 。
- 将请求 转发给服务器。
- 拿到服务器 响应 数据。
// index.html(http://127.0.0.1:5500) <script src="https://cdn.bootcss.com/jquery/3.3.1/jquery.min.js"></script> <script> $.ajax({ url: 'http://localhost:3000', type: 'post', data: { name: 'xiamen', password: '123456' }, contentType: 'application/json;charset=utf-8', success: function(result) { console.log(result) // {"title":"fontend","password":"123456"} }, error: function(msg) { console.log(msg) } }) </script>1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// server1.js 代理服务器(http://localhost:3000) const http = require('http') // 第一步:接受客户端请求 const server = http.createServer((request, response) => { // 代理服务器,直接和浏览器直接交互,需要设置CORS 的首部字段 response.writeHead(200, { 'Access-Control-Allow-Origin': '*', 'Access-Control-Allow-Methods': '*', 'Access-Control-Allow-Headers': 'Content-Type' }) // 第二步:将请求转发给服务器 const proxyRequest = http .request( { host: '127.0.0.1', port: 4000, url: '/', method: request.method, headers: request.headers }, serverResponse => { // 第三步:收到服务器的响应 var body = '' serverResponse.on('data', chunk => { body += chunk }) serverResponse.on('end', () => { console.log('The data is ' + body) // 第四步:将响应结果转发给浏览器 response.end(body) }) } ) .end() }) server.listen(3000, () => { console.log('The proxyServer is running at http://localhost:3000') })1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38// server2.js(http://localhost:4000) const http = require('http') const data = { title: 'fontend', password: '123456' } const server = http.createServer((request, response) => { if (request.url === '/') { response.end(JSON.stringify(data)) } }) server.listen(4000, () => { console.log('The server is running at http://localhost:4000') })1
2
3
4
5
6
7
8
9
10
11上述代码经过两次跨域,值得注意的是浏览器向代理服务器发送请求,也遵循同源策略,最后在index.html文件打印出
{"title":"fontend","password":"123456"}🌙 nginx反向代理
// proxy服务器 server { listen 81; server_name www.domain1.com; location / { proxy_pass http://www.domain2.com:8080; #反向代理 proxy_cookie_domain www.domain2.com www.domain1.com; #修改cookie里域名 index index.html index.htm; # 当用webpack-dev-server等中间件代理接口访问nignx时,此时无浏览器参与,故没有同源限制,下面的跨域配置可不启用 add_header Access-Control-Allow-Origin http://www.domain1.com; #当前端只跨域不带cookie时,可为* add_header Access-Control-Allow-Credentials true; } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
🌙 9.解释简单请求和非简单请求? 跨域如何带上cookie?
- 简单请求
不会触发CORS预检的请求称为简单请求,满足以下所有条件的才会被视为简单请求,基本上我们日常开发只会关注前面两点(一般满足前两大条件,就属于简单请求:)
1.使用GET、POST、HEAD其中一种方法 2.只使用了如下的安全首部字段,不得人为设置其他首部字段:
Accept
Accept-Language
Content-Language
Content-Type 仅限以下三种
- text/plain
- multipart/form-data
- application/x-www-form-urlencoded
HTML头部header field字段:DPR、Download、Save-Data、Viewport-Width、WIdth
请求中的任意XMLHttpRequestUpload 对象均没有注册任何事件监听器;XMLHttpRequestUpload 对象可以使用 XMLHttpRequest.upload 属性访问
请求中没有使用 ReadableStream 对象
非简单请求
满足下列之一,就为非简单请求:
1.请求方式:PUT、DELETE
2.自定义头部字段
3.发送json格式数据
4.正式通信之前,浏览器会先发送OPTION请求,进行预检,这一次的请求称为“预检请求”
5.服务器成功响应预检请求后,才会发送真正的请求,并且携带真实数据
规范要求,对那些可能对服务器数据产生副作用的 HTTP 请求方法(特别是 GET 以外的 HTTP 请求,或者搭配某些 MIME 类型的 POST 请求),浏览器必须首先使用 OPTIONS 方法发起一个预检请求(preflight request),从而获知服务端是否允许该跨域请求。
- 跨域cookie携带
一般来说,对于跨站请求,浏览器是不会发送凭证(HTTP Cookies和验证信息)的。如果要发送带凭证的信息,只需要给XMLHttpRequest设置一个特殊的属性withCredentials = true,通过这种方式,浏览器就允许发送凭证信息。

🌙 10.React 事件系统理解
- react的所有事件都挂载在document中
- 当真实dom触发后冒泡到document后才会对react事件进行处理
- 所以原生的事件会先执行
- 然后执行react合成事件
- 最后执行真正在document上挂载的事件
🌙 11.React事件阻止冒泡
import React from 'react';
class Demo extends React.Component {
componentDidMount() {
this.parent.addEventListener('click', (e) => {
console.log('dom parent');
})
this.child.addEventListener('click', (e) => {
console.log('dom child');
// A.加了这个之后会怎么样 ?
// e.stopPropagation()
})
document.addEventListener('click', (e) => {
console.log('document');
})
}
childClick = (e) => {
console.log('react child')
// B.加了这个之后又会怎么样 ?
// e.stopPropagation()
}
parentClick = (e) => {
console.log('react parent');
}
render() {
return (
<div onClick={this.parentClick} ref={ref => this.parent = ref}>
<div onClick={this.childClick} ref={ref => this.child = ref}>
test
</div>
</div>
)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
- 不加任何'e.stopPropagation()',打印结果:
"addEventListener child"
"addEventListener parent"
"onClick child"
"onClick parent"
"document"
2
3
4
5
- A.在this.child.addEventListener中加入'e.stopPropagation()',打印结果:
"addEventListener child"
- B.在childClick中加入'e.stopPropagation()',打印结果:
"addEventListener child"
"addEventListener parent"
"onClick child" // 阻止了合成事件的冒泡,但阻止不了原生事件
"document"
2
3
4
See the Pen React 测试e.stopPropagation() by Keekuun (@keekuun) on CodePen.
🌙 12. React.useEffect 和 useLayoutEffect 的执行顺序
function Demo() {
const [count, setCount] = React.useState(0);
React.useEffect(() => {
console.log("useEffect");
return () => {
console.log("useEffect return");
};
});
React.useLayoutEffect(() => {
console.log("useLayoutEffect");
return () => {
console.log("useLayoutEffect return");
};
});
const add = () => {
const n = count + 1;
setCount(n);
};
console.log('render');
return (
<Button type="primary" onClick={add}>
{count}
</Button>
);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
初始化时,输出结果:
"render"
"useLayoutEffect"
"useEffect"
2
3
点击button,输出结果:
"render"
"useLayoutEffect return"
"useLayoutEffect"
"useEffect return"
"useEffect"
2
3
4
5
🌙 12.1useEffect 和 useLayoutEffect 的区别?
useEffect 在渲染时是异步执行,并且要等到浏览器将所有变化渲染到屏幕后才会被执行。
useLayoutEffect 在渲染时是同步执行,其执行时机与 componentDidMount,componentDidUpdate 一致
🌙 12.2 对于 useEffect 和 useLayoutEffect 哪一个与 componentDidMount,componentDidUpdate 的是等价的?
useLayoutEffect,因为从源码中调用的位置来看,useLayoutEffect的 create 函数的调用位置、时机都和 componentDidMount,componentDidUpdate 一致,且都是被 React 同步调用,都会阻塞浏览器渲染。
🌙 12.3 useEffect 和 useLayoutEffect 哪一个与 componentWillUnmount 的是等价的?
同上,useLayoutEffect 的 destroy 函数的调用位置、时机与 componentWillUnmount 一致,且都是同步调用。useEffect 的 destroy 函数从调用时机上来看,更像是 componentDidUnmount (注意React 中并没有这个生命周期函数)。
🌙 12.4 为什么建议将修改 DOM 的操作里放到 useLayoutEffect 里,而不是 useEffect?
当DOM 已经被修改时,此时浏览器渲染线程依旧处于被阻塞阶段,所以还没有发生回流、重绘过程。由于内存中的 DOM 已经被修改,通过 useLayoutEffect 可以拿到最新的 DOM 节点,并且在此时对 DOM 进行样式上的修改,假设修改了元素的 height,这些修改会和 react 做出的更改一起被一次性渲染到屏幕上,依旧只有一次回流、重绘的代价。
如果放在 useEffect 里,useEffect 的函数会在组件渲染到屏幕之后执行,此时对 DOM 进行修改,会触发浏览器再次进行回流、重绘,增加了性能上的损耗。
🌙 13.解释箭头函数 和 this 指向
var a = 99;
var obj = {
a: 1024,
say1: () => {
console.log(this.a);
},
say2: function() {
console.log(this.a);
},
say3(){
console.log(this.a);
}
}
obj.say1(); // 99
obj.say2(); // 1024
obj.say3(); // 1024
obj.say1.apply({a: 8989}); // 99
var say = obj.say1;
say() // 99
var obj = {a: 1}
var foo = {}
foo[obj] = true; // {"object Object": true}
Object.keys(foo) // [["object Object"]]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
箭头函数,没有它自己的this值,箭头函数内的this值继承自外围作用域。在箭头函数中调用 this 时,仅仅是简单的沿着作用域链向上寻找,找到最近的一个 this 拿来使用。
箭头函数在定义之后,this 就不会发生改变了,无论用什么样的方式调用它,this 都不会改变;
🌙 14、不重复数
🌙 给定一个id数组和数字m,从数组中取出m个id,求剩余最小不重复id的个数。
ids = [1,2,3,3,3,2]; m = 2;
function removeKMinnumUniqueNum(arr, k) {
let len = arr.length;
if(k >= len) return 0;
let obj = {}; // {1: 1, 2: 2, 3: 3}
for(let n of arr) {
obj[n] = (obj[n] || 0) + 1;
}
let sortedNumArr = Object.keys(obj).map(key => [key, obj[key]]).sort((a, b) => a[1] - b[1]);
let ans = sortedNumArr.length;
for(let item of sortedNumArr) {
if(item[1] <= k) {
k = k - item[1];
ans--;
}
}
return ans;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
🌙 15.排序问题
有一个数组需要排序排序,排序顺序是先按数字多少排,越少的排越前面,越小的排越前面,比如[6,55,1,2,1],这种,返回值就是[2,6,55,1,1]
function sortNum(arr) {
if(arr.length < 2) return arr;
let obj = {};
arr.reduce((acc, cur) => {
acc[cur] = (acc[cur] || 0) + 1;
return acc;
}, obj);
return Object.keys(obj).map(key => [+key, obj[key]]).sort((a, b) => {
if(a[1] === b[1]) {
return a[0] - b[0]
} else {
return a[1] - b[1]
}
}).flatMap(d => new Array(d[0]).fill(d[1]));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
🌙 测试题二
🌙 1.http 301 302 307 的区别
301 Move Permanently 永久重定向。表明目标资源被永久的移动到了一个新的 URI,任何未来对这个资源的引用都应该使用新的 URI。GET ---> POST
302 Found 临时重定向。表示目标资源临时移动到了另一个 URI 上。由于重定向是临时发生的,所以客户端在之后的请求中还应该使用原本的 URI。POST ---> GET
服务器会在响应 Header 的 Location 字段中放上这个不同的 URI。浏览器可以使用 Location 中的 URI 进行自动重定向。
由于历史原因,用户代理可能会在重定向后的请求中把 POST 方法改为 GET 方法。如果不想这样,应该使用 307(Temporary Redirect) 状态码。
303 See Other 临时重定向。表示服务器要将浏览器重定向到另一个资源,这个资源的 URI 会被写在响应 Header 的 Location 字段。从语义上讲,重定向到的资源并不是你所请求的资源,而是对你所请求资源的一些描述。
303 常用于将 POST 请求重定向到 GET 请求,比如你上传了一份个人信息,服务器发回一个 303 响应,将你导向一个“上传成功”页面。POST ---> GET
不管原请求是什么方法,重定向请求的方法都是 GET(或 HEAD,303不常用)。
307 Temporary Redirect 临时重定向。307 的定义实际上和 302 是一致的,唯一的区别在于,307 状态码不允许浏览器将原本为 POST 的请求重定向到 GET 请求上。POST ---\--> GET
308 Permanent Redirect 永久重定向。308 的定义实际上和 301 是一致的,唯一的区别在于,308 状态码不允许浏览器将原本为 POST 的请求重定向到 GET 请求上。GET ---\--> POST
302 与 303、307 的关系:
从实际效果看:302 允许各种各样的重定向,一般情况下都会实现为到 GET 的重定向,但是不能确保 POST 会重定向为 POST;而 303 只允许任意请求到 GET 的重定向;307 和 302 一样,除了不允许 POST 到 GET 的重定向。
🌙 2.301 和 302 哪个对 seo 更友好(301)
如果你要将内容永久移动到新位置,请使用 301 重定向。如你果要临时移动它,请使用 302 重定向。
使用301:
- 你将永久更改网页的 URL时。
- 你将永久迁移到新域名时。
- 当你从 HTTP 切换到 HTTPS (opens new window) 时。
- 你希望修复非 www / www 重复内容 (opens new window)问题时。
- 永久合并两个或多个页面或网站时。
- 你将永久更改网站的 URL 结构时。
使用302:
- 当你想将用户重定到正确的网站版本(基于位置/语言)时。
- 当你要对网页的功能或设计进行 A / B 拆分测试时。
- 你希望在不影响旧页面排名的情况下获得新页面的反馈时。
- 当你正在进行促销,并希望暂时将访问者重定向到促销页面时。
搜索引擎对待 301 重定向和 302 重定向的方式不同。
当一个 URL 重定向到另一个 URL 时,Google 只会保留其中一个 URL 的索引。
302跳转是暂时的跳转,搜索引擎会抓取新的内容而保留旧的网址。因为服务器返回302代码,搜索引擎认为新的网址只是暂时的。
301重定向是永久的重定向,搜索引擎在抓取新内容的同时也将旧的网址替换为重定向之后的网址。推荐301,对SEO更友好
🌙 3.跨域是什么、如何解决
🌙 4.jsonp 有什么缺点
优点:兼容性好
缺点:
1.错误处理机制不完善
2.存在安全问题:
安全防范:
1.防止callback参数意外截断js代码,特殊字符单引号双引号,换行符存在风险.
2.防止callback参数恶意添加script标签,造成xss漏洞
3.防止跨域请求滥用,阻止非法站点恶意调用
2
3
4
5
6
3.只支持GET,不支持POST
4.需要后端配合使用
🌙 5.base64和外链的应用场景,各自的优缺点
- base64:使用64个字符来对任意数据进行编码
- 优点:可以将二进制数据转化为可打印字符,方便传输数据,对数据进行简单的加密,肉眼安全。可以减少http请求(处理小图片或字体文件) 缺点:内容编码后体积变大,编码和解码需要额外工作量。
使用场景:
1.Base64一般用于在HTTP协议下传输二进制数据,由于HTTP协议是文本协议,所以在HTTP写一下传输二进制数据需要将二进制数据转化为字符数据,
网络传输只能传输可打印字符,
在ASCII码中规定,0-31、128这33个字符属于控制字符,
32~127这95个字符属于可打印字符
那么其它字符怎么传输呢,Base64就是其中一种方式,
2.将图片等资源文件以Base64编码形式直接放于代码中,使用的时候反Base64后转换成Image对象使用。
3.偶尔需要用这条纯文本通道传一张图片之类的情况发生的时候,就会用到Base64,比如多功能Internet 邮件扩充服务(MIME)就是用Base64对邮件的附件进行编码的。
2
3
4
5
6
7
8
- 外链:
打开链接方式:
// 1.使用window.open
var win = window.open();
win.opener = null; // 会让新窗口运行在独立的进程里,不会拖累原来页面的进程
win.location = "http://someurl.here";
win.target = "_blank";
// a标签,安全考虑加上rel="noopener noreferer"
<a href="" target="__blank" rel="noopener noreferer">
2
3
4
5
6
7
8
🌙 6.http缓存机制
🌙 7.https 的握手过程
🌙 8.Set/Map 、weakSet/weakMap的区别
WeakMap 弱引用的只是键名,而不是键值。键值依然是正常引用
- Set
- 成员唯一、无序且不重复
- [value, value],键值与键名是一致的(或者说只有键值,没有键名)
- 可以遍历,方法有:add、delete、has
- WeakSet
- 成员都是对象
- 成员都是弱引用,可以被垃圾回收机制回收,可以用来保存DOM节点,不容易造成内存泄漏
- 不能遍历,方法有add、delete、has
- Map
- 本质上是键值对的集合,类似集合
- 可以遍历,方法很多可以跟各种数据格式转换
- WeakMap
- 只接受对象作为键名(null除外),不接受其他类型的值作为键名
- 键名是弱引用,键值可以是任意的,键名所指向的对象可以被垃圾回收,此时键名是无效的
- 不能遍历,方法有get、set、has、delete
🌙 9.hook 的局限性
🌙 10.setState 和 hook 的区别
🌙 11.decorator 的作用,编译后是什么样子的
装饰器对类的行为的改变,是代码编译时发生的,而不是在运行时。这意味着,装饰器能在编译阶段运行代码。也就是说,装饰器本质就是编译时执行的函数。
- 装饰类 - @decorator
// target 就是构造函数 Foo
function print(target){
console.log(target)
}
// 编译前,注意,在这里我们的使用方式是 `@print` 而不是 `@print()`。
@print
class Foo(){}
// 编译后
var Foo =
print(
(_class = function Foo() {})
) || _class;
2
3
4
5
6
7
8
9
10
11
12
13
14
由于 print 函数返回 undefined,所以 Foo 在这里仍是 Foo。那当我们装饰器写成 @print() 时,又会发生什么?
- 装饰类 - @decorator()
// 编译后
var Foo = ((_dec = print()),
_dec(
(_class = ((_temp = function Foo() {
_classCallCheck(this, Foo);
this.a = 1;
this.b = 2;
}),
_temp))
) || _class);
复制代码
2
3
4
5
6
7
8
9
10
11
12
可以发现首先执行 print 函数,但是由于 print 返回 undefined,所以当执行 dec() 直接报错。
🌙 12.Symbol 是什么,一般用来做什么
Symbol 可以创建一个独一无二的值(但并不是字符串),是ES6引进的一种基本数据类型。
阻止对象属性名冲突
🌙 模拟私有属性
let proxy; { const favBook = Symbol('fav book'); const obj = { name: 'Thomas Hunter II', age: 32, _favColor: 'blue', [favBook]: 'Metro 2033', [Symbol('visible')]: 'foo' }; const handler = { ownKeys: (target) => { const reportedKeys = []; const actualKeys = Reflect.ownKeys(target); for (const key of actualKeys) { if (key === favBook || key === '_favColor') { continue; } reportedKeys.push(key); } return reportedKeys; } }; proxy = new Proxy(obj, handler); } // 'Metro 2033' 这个属性是看不到的 console.log(Object.keys(proxy)); // [ 'name', 'age' ] console.log(Reflect.ownKeys(proxy)); // [ 'name', 'age', Symbol(visible) ] console.log(Object.getOwnPropertyNames(proxy)); // [ 'name', 'age' ] console.log(Object.getOwnPropertySymbols(proxy)); // [Symbol(visible)] console.log(proxy._favColor); // 'blue'1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
🌙 13.csrf 是什么,如何防范
CSRF(Cross-site request forgery),中文名称:跨站请求伪造。
简单理解:用户登录了a页面,a页面中有用户的隐私信息(如:cookie),之后在a页面被诱惑引导进入b页面,将a页面的cookie带到b页面,b页面通过cookie伪造a页面身份骗取服务端的信任。(设置XMLHttpRequest.withCredentials (opens new window) : true可以自动带上cookie)
防止:
1.验证 HTTP Referer 字段
2.使用验证码
3.在请求地址中添加token并验证 Authorization
4.在HTTP 头中自定义属性并验证
注意: 设置http-only是用来防止xss攻击的(使cookie不能通过js获取)。CSP (opens new window)也是用来防止xss攻击
🌙 14.sql注入是什么,如何防范
SQL注入是一种注入攻击,,可以执行恶意SQL语句
1 )严格检查输入变量的类型和格式对于整数参数,加判断条件:不能为空、参数类型必须为数字对于字符串参数,可以使用正则表达式进行过滤:如:必须为[0-9] [a-z] [A-Z]范围内的字符串
2 )过滤和转义特殊字符,对'、"、等特殊字符进行转义
3 )利用 mysql 的预编译机制
🌙 15.react 调用 setState 之后发生什么
在react中触发状态更新的几种方式:
- ReactDOM.render
- this.setState
- this.forceUpdate
- useState
- useReducer
在代码中调用setState函数之后,React 会将传入的参数对象与组件当前的状态合并,然后触发所谓的调和过程(Reconciliation)。 经过调和过程,React 会以相对高效的方式根据新的状态构建React 元素树并且着手重新渲染整个UI界面。
1.this.setState内调用this.updater.enqueueSetState
2.this.forceUpdate和this.setState一样,只是会让tag赋值ForceUpdate
3.enqueueForceUpdate之后会经历创建update,调度update等过程
🌙 16.nodejs 事件循环机制
事件循环是指Node.js执行非阻塞I/O操作。当Node.js启动时会初始化event loop, 每一个event loop都会包含按如下顺序六个循环阶段:
┌───────────────────────┐
┌─>│ timers │ `setTimeout(callback)` 和 `setInterval(callback)`
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
│ │ I/O callbacks │ 某些系统操作的回调
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
│ │ idle, prepare │ 仅node内部使用
│ └──────────┬────────────┘ ┌───────────────┐
│ ┌──────────┴────────────┐ │ incoming: │
│ │ poll │<─────┤ connections, │ 获取新的I/O事件, 例如操作读取文件
│ └──────────┬────────────┘ │ data, etc. │
│ ┌──────────┴────────────┐ └───────────────┘
│ │ check │ 执行 `setImmediate()`
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
└──┤ close callbacks │ `socket.on('close', callback)`
└───────────────────────┘
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
timers阶段: 这个阶段执行setTimeout(callback)和setInterval(callback)预定的 callback;I/O callbacks阶段: 此阶段执行某些系统操作的回调,例如TCP错误的类型。 例如,如果TCP套接字在尝试连接时收到 ECONNREFUSED,则某些* nix系统希望等待报告错误。 这将操作将等待在==I/O回调阶段==执行;idle, prepare阶段: 仅node内部使用;poll阶段: 获取新的I/O事件, 例如操作读取文件等等,适当的条件下node将阻塞在这里;
- 技术上来说,poll 阶段控制 timers 什么时候执行。
check阶段: 执行setImmediate()设定的callbacks;close callbacks阶段: 比如socket.on(‘close’, callback)的callback会在这个阶段执行;
🌙 17.pm2原理,有哪些模式(cluster fork)
pm2 (opens new window) 是我们在使用 Node 开发时常用的服务托管工具
🌙 18.docker 和 k8s 有了解多少
🌙 19. 移动端一个元素的拖动,如何实现和优化(节流,改变位置)
🌙 20. for in / for of
for in: 用来遍历对象或数组
for of:遍历对数组
🌙 21.描述链表的反转如何实现,复杂度多少
// 反转链表
function reverse(root) {
let pre = null;
let cur = root;
while(cur) {
let next = cur.next;
cur.next = pre;
pre = cur;
cur = next;
}
return pre;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
🌙 22.实现 instanceof
function _instance(L, R) {
let O = R.prototype;
while(true) {
if(L === null) return false;
if(L === O) return true;
L = L.__proto__
}
}
2
3
4
5
6
7
8
9
🌙 23.实现一个对象被 for of 遍历
function iteratored(obj) {
let data = [];
for(let key in obj) {
if(obj.hasOwnProperty(key)) {
data.push([key, obj[key]])
}
};
let index = -1;
return {
next() {
index++;
return ({
value: data[index],
done: index === data.length
})
},
[Symbol.iterator](){
return this;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
🌙 24.实现链表的添加、删除。复杂度是多少
function add() {
}
function delete() {
}
2
3
4
5
6
7
🌙 25.给两段效果上都可以实现继承的代码,说出差异
function child() {}
function parent() {}
child.prototype.__proto__ = parent.prototype;
child.prototype = new parent();
2
3
4
5
6
7
🌙 26.this 输出问题
🌙 27.如何监听 html 外链资源加载失败?
// 1.window.onerror 无法监听到资源加载错误,是因为 window.onerror 是在事件冒泡阶段执行的
window.addEventListener('error', e => { // 捕获阶段
console.log('错误监听', e);
}, true);
try {} catch (err) {
console.error(err);
}
// 2.script onerror
<script onerror="onError(this)"></script>
// 3.img/video onerror
<img src="https://www.github.com/static/xxxxx.png" onerror="handleImgErr()" alt="" srcset="">
<video src="https://www.gitee.com/staic/xxxx.mp4" onerror="handleVideoErr()"></video>
function postError(type, msg) {
const img = new Image();
img.src = `api/log?type=${encodeURICoponent(type)}&msg=${encodeURICoponent(msg)}`
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
🌙 28.Mutation Observer、IntersectionObserver 使用场景
MutationObserver: 监听dom的变化。
IntersectionObserver:观察目标元素与视口或指定根元素产生的交叉区的变化,是否可见
懒加载
function query(selector) { return Array.from(document.querySelectorAll(selector)); } var observer = new IntersectionObserver( function(changes) { changes.forEach(function(change) { var container = change.target; var content = container.querySelector('template').content; container.appendChild(content); observer.unobserve(container); }); } ); query('.lazy-loaded').forEach(function (item) { observer.observe(item); });1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19无限滚动
var intersectionObserver = new IntersectionObserver( function (entries) { // 如果不可见,就返回 if (entries[0].intersectionRatio <= 0) return; loadItems(10); console.log('Loaded new items'); }); // 开始观察 intersectionObserver.observe( document.querySelector('.scrollerFooter') );1
2
3
4
5
6
7
8
9
10
11
12See the Pen IntersectionObserver无限滚动 by Keekuun (@keekuun) on CodePen.
🌙 29. 127.0.0.1 和 0.0.0.0 差别(一个只能通过 localhost ,另一个可以通过本机 ip 或者 localhost 都可以)
127.0.0.1 是一个环回地址, 一般使用localhost访问的就是这个地址,并不表示“本机”。0.0.0.0才是真正表示“本网络中的本机”。
🌙 30.利用 Promise js sleep 函数实现
function sleep(time) {
return new Promise(resolve => {
setTimeout(() => resolve(), time)
})
}
2
3
4
5
🌙 31.jsx 转换后是什么样子的
function Comp() {
return <span>hello</span>;
}
function App() {
return (
<div id="test">
<Comp />
<ul>
<li>1</li>
<li>2</li>
</ul>
</div>
);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
经过 babel 编译后,生成如下代码:
function Comp() {
return React.createElement("span", null, "hello");
}
function App() {
return React.createElement(
"div",
{
id: "test"
},
React.createElement(Comp, null),
React.createElement(
"ul",
null,
React.createElement("li", null, "1"),
React.createElement("li", null, "2")
)
);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
ReactElement代码:
const ReactElement = function(type, key, ref, self, source, owner, props) {
const element = {
$$typeof: REACT_ELEMENT_TYPE,
type: type,
key: key,
ref: ref,
props: props,
_owner: owner
};
return element;
};
function createElement(type, config, children) {
return ReactElement(
type,
key,
ref,
self,
source,
ReactCurrentOwner.current,
props
);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
🌙 32.redux compose 函数是做什么的,中间件呢
Compose 用来实现函数组合,是函数式编程中很重要的概念,可以用来组合多个 Redux 中间件方法。
Redux利用中间件来扩展自身功能,以满足用户的开发需求,于redux 提供了 applyMiddleware 方法来加载 middleware。
applyMiddleware 这个函数的核心就在于在于组合 compose,,通过将不同的 middlewares 一层一层包裹到原生的 dispatch 之上,然后对 middleware 的设计采用柯里化的方式,以便于compose ,从而可以动态产生 next 方法以及保持 store 的一致性。
// compose
function compose(...fns) {
if (fns.length === 0) {
return a => a;
}
if (fns.length === 1) {
return fns[0];
}
var fn = fns.reduce((a, b) => {
return (...args) => {
return a(b(...args));
};
});
return fn;
}
// applyMiddleware
function applyMiddleware(...middlewares) {
return createStore => (...args) => {
// 利用传入的createStore和reducer和创建一个store
const store = createStore(...args)
let dispatch = () => {
throw new Error(
)
}
const middlewareAPI = {
getState: store.getState,
dispatch: (...args) => dispatch(...args)
}
// 让每个 middleware 带着 middlewareAPI 这个参数分别执行一遍
const chain = middlewares.map(middleware => middleware(middlewareAPI))
// 接着 compose 将 chain 中的所有匿名函数,组装成一个新的函数,即新的 dispatch
dispatch = compose(...chain)(store.dispatch)
return {
...store,
dispatch
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
🌙 33.redux-sage 是什么,和 redux-thunk 有什么区别
Redux Thunk和Redux Saga都负责处理副作用。在大多数场景中,Thunk 使用Promises来处理它们,而 Saga 使用Generators。Thunk 易于使用,因为许多开发人员都熟悉 Promise,Sagas/Generators 功能更强大,但您需要学习它们。但是这两个中间件可以共存,所以你可以从 Thunks 开始,并在需要时引入 Sagas。
🌙 34.dva 了解吗
dva 首先是一个基于 redux (opens new window) 和 redux-saga (opens new window) 的数据流方案,然后为了简化开发体验,dva 还额外内置了 react-router (opens new window) 和 fetch (opens new window),所以也可以理解为一个轻量级的应用框架。
dva框架封装了Redux 架构一些繁琐、复杂的步骤和常用库,使用dva,不会构建Redux架构也可以,dva帮你做好了;
dva 降低了组件之间的耦合度,没有父子、兄弟组件的关系,提高了组件可重用性以及渲染性能,使思路变得简单清晰;
dva架构思路清晰,代码书写方式固定,有利于团队合作,但可扩展性不强
[DvaJS (opens new window)](https://dvajs.com/guide/)
🌙 35.umi.js 有用过吗?
🌙 36.req.pipe(res)
把一个 readable stream 的所有数据写入到另一个 writable stream 里面、
express 的 req 派生自 IncomingMessage (opens new window),而这个类实现了 readable stream 的所有方法。
🌙 37.stream 如何处理数据消费和数据生产的速率不一致问题
如果 Readable 读入数据的速率大于 Writable 写入速度的速率,这样就会积累一些数据在缓冲区,如果缓冲的数据过多,就会爆掉,会丢失数据。
而如果 Readable 读入数据的速率小于 Writable 写入速度的速率呢?那没关系,最多就是中间有段空闲时期。
怎么解决这种读写速率不一致的问题呢?
当没写完的时候,暂停读就行了。这样就不会读入的数据越来越多,驻留在缓冲区。
readable stream 有个 readableFlowing 的属性,代表是否自动读入数据,默认为 true,也就是自动读入数据,然后监听 data 事件就可以拿到了。
当 readableFlowing 设置为 false 就不会自动读了,需要手动通过 read 来读入。
pipe 就没有这个问题,因为内部做了读入速率的动态调节.
const rs = fs.createReadStream(src);
const ws = fs.createWriteStream(dst);
// 当调用 writable stream 的 write 方法的时候会返回一个 boolean 值代表是写入了目标还是放在了缓冲区:
// true: 数据已经写入目标
// false:目标不可写入,暂时放在缓冲区
// 可以判断返回 false 的时候就 pause,然后等缓冲区清空了就 resume
rs.on('data', function (chunk) {
if (ws.write(chunk) === false) {
rs.pause();
}
});
rs.on('end', function () {
ws.end();
});
ws.on('drain', function () {
rs.resume();
});
// 使用pipe
const rs = fs.createReadStream(src);
const ws = fs.createWriteStream(dst);
rs.pipe(ws);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
🌙 38.writeable stream drain 事件是做什么的?
控制读写速率
drain事件:当一个流不处在 drain 的状态, 对 write() 的调用会缓存数据块, 并且返回 false。 一旦所有当前所有缓存的数据块都排空了(被操作系统接受来进行输出), 那么 'drain' 事件就会被触发
🌙 测试题三
🌙 1.JS继承
function Parent() {
this.name = 'Parent';
this.getName = function() { // 会覆盖 prototype.getName
return this.name + ' inner';
}
this.getName1 = function() {
return this.name + ' inner1';
}
this.getName2 = () => {
return this.name + ' inner2';
}
}
Parent.prototype.getName = function(){
return this.name; // // 此处this并指向Parent
}
Parent.prototype.getName = () => {
return this.name; // 此处this并不指向Parent,指向上层作用域的this,比如: window
}
Parent.prototype.greet = function() {
return 'hello ' + this.name;
}
function Child() {
this.name = 'Child';
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
🌙 1.2 原型链继承
Child.prototype = new Parent();
let child1 = new Child();
let child2 = new Child();
child1.getName();
2
3
4
5
缺点:多个实例共享一个内存空间,有篡改风险
🌙 1.3 构造函数继承(call)
function Child() {
Parent.call(this);
this.name = 'child';
}
let child1 = new Child();
child1.greet() // error
2
3
4
5
6
7
优点:解决多个实例共享同一个内存的问题
缺点:子类无法继承父类原型对象中的方法
🌙 1.4 组合继承
function Child() {
Parent.call(this);
this.name = 'child';
}
Child.prototype = new Parent();
Child.prototype.constructor = Child;
2
3
4
5
6
7
优点:解决了前两种继承方式的缺陷
缺点:父类构造函数执行了两次,造成浪费
🌙 1.5 原型式继承(Object.create)
let Parent = {
name: 'parent',
getName: function(){
return this.name; // // 正常访问
},
getName1() {
return this.name + '1'; ; // 正常访问
},
getName2: () => {
return this.name + '2'; // this指向上层作用域
},
};
let child = Object.create(Parent);
2
3
4
5
6
7
8
9
10
11
12
13
优点:可以继承属性以及属性方法
缺点:无法解决共享问题(同1.2)
🌙 1.6 寄生式继承
let Parent = {
name: 'parent',
getName: function(){
return this.name; // // 正常访问
},
getName1() {
return this.name + '1'; ; // 正常访问
},
getName2: () => {
return this.name + '2'; // this指向上层作用域
},
};
function clone(target) {
let _clone = Object.create(target);
_clone.getName = function(){
return this.name + ' clone';
}
return _clone;
}
let child = clone(Parent);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
优点:可以在继承的基础上新增自定义方法
🌙 1.7 组合寄生式继承(最佳)
function clone(parent, child) {
child.prototype = Object.create(parent.prototype);
child.prototype.constructor = child;
}
function Parent(){}
function Child(){
Parent.call(this);
}
clone(Parent, Child)
2
3
4
5
6
7
8
9
10
优点:解决多个实例共享的问题;解决组合式继承父类构造函数多次调用的性能开销问题
🌙 1.8 ES6 Extends继承
es6继承是组合寄生式继承(最佳)的语法糖,底层实现逻辑和组合寄生式继承一般无二。
function _inherits(subClass, superClass) {
subClass.prototype = Object.create(superClass && superClass.prototype, {
constructor: {
value: subClass,
enumerable: false,
writable: true,
configure: true
}
});
if(superClass) Object.setPrototypeOf ? Object.setPrototypeOf(subClass, superClass) : subClass.__proto__ = superClass;
}
2
3
4
5
6
7
8
9
10
11
12
🌙 2.实例属性和原型属性的区别
- 1.实例属性指的是在构造函数方法中定义的属性和方法,每一个实例对象都独立开辟一块内存空间用于保存属性和方法。
// 1.实例属性指的是在构造函数方法中定义的属性和方法,每一个实例对象都独立开辟一块内存空间用于保存属性和方法。
function Products() {
this.name = 'car',
this.ids = [1,2]
}
var product1 = new Products();
var product2 = new Products();
product1.ids[0] = 3;
console.log(product1.ids); //[3,2]
console.log(product2.ids); //[1,2]
2
3
4
5
6
7
8
9
10
11
- 2.原型属性指的是用于创建实例对象的构造函数的原型的属性,每一个创建的实例对象都共享原型属性。
// 2.原型属性指的是用于创建实例对象的构造函数的原型的属性,每一个创建的实例对象都共享原型属性。
function Products() {
this.name = 'car',
this.ids = [1,2]
}
Products.prototype.type = ['a', 'b'];
var product1 = new Products();
var product2 = new Products();
product1.type[0] = 'c';
console.log(product1.type); //["c", "b"]
console.log(product2.type); //["c", "b"]
2
3
4
5
6
7
8
9
10
11
🌙 4.instanceof 的原理
instanceof 内部机制是通过原型链来实现的:
function instance_of(L, R) { // L 表示instanceof左边,R 表示instanceof右边
let O = R.prototype; // 取 R 的显示原型
L = L.__proto__; // 取 L 的隐式原型
while (true) { // 循环执行,直到 O 严格等于 L
if (L === null) return false;
if (O === L) return true;
L = L.__proto__;
}
}
2
3
4
5
6
7
8
9
10
🌙 5.浏览器缓存刷新
刷新:
- 打开网页,地址栏输入地址: 查找
disk cache中是否有匹配。如有则使用;如没有则发送网络请求。 - 普通刷新 (F5):因为 TAB 并没有关闭,因此
memory cache是可用的,会被优先使用(如果匹配的话)。其次才是disk cache。 - 强制刷新 (Ctrl + F5):浏览器不使用缓存,因此发送的请求头部均带有
Cache-control:no-cache(为了兼容,还带了Pragma:no-cache),服务器直接返回 200 和最新内容
🌙 6.缓存位置
Service Worker
Service Worker 的缓存与浏览器其他内建的缓存机制不同,它可以让我们自由控制缓存哪些文件、如何匹配缓存、如何读取缓存,并且缓存是持续性的。
Memory Cache
内存中的缓存,主要包含的是当前中页面中已经抓取到的资源,例如页面上已经下载的样式、脚本、图片等。读取内存中的数据肯定比磁盘快,内存缓存虽然读取高效,可是缓存持续性很短,会随着进程的释放而释放。一旦我们关闭 Tab 页面,内存中的缓存也就被释放了。
Disk Cache
Disk Cache 也就是存储在硬盘中的缓存,读取速度慢点,但是什么都能存储到磁盘中,比之 Memory Cache 胜在容量和存储时效性上。
Push Cache
Push Cache(推送缓存)是 HTTP/2 中的内容,当以上三种缓存都没有命中时,它才会被使用。它只在会话(Session)中存在,一旦会话结束就被释放,并且缓存时间也很短暂,在 Chrome 浏览器中只有 5 分钟左右,同时它也并非严格执行 HTTP 头中的缓存指令。
🌙 7.Service Worker
- LocalStorage 使用的缓存限制大小为
5MB-10MB - indexedDB 缓存的大小限制最大为
50MB。 - Service Worker 所能使用的容量大小不做统一限制,而是由当前电脑的磁盘空间所限制。(iOS Safari 限制为50MB)
Service Worker 生命周期:
install -> installed -> actvating -> Active -> Activated -> Redundant
Service Worker 使用细节:
- Service Worker 必须在 HTTPS 协议下使用
- Service Worker 的作用域限制在其脚本存放路径上
🌙 8.Push Cache 的具体处理方式
- Service Worker
- Memory Cache
- Disk Cache
- Push Cache
Push Cache(推送缓存)是 HTTP/2 中的内容,当以上三种缓存都没有命中时,它才会被使用。它只在会话(Session)中存在,一旦会话结束就被释放,并且缓存时间也很短暂,在 Chrome 浏览器中只有 5 分钟左右,同时它也并非严格执行 HTTP 头中的缓存指令。
Push Cache的几个结论:
- 所有的资源都能被推送,并且能够被缓存,但是 Edge 和 Safari 浏览器支持相对比较差;
- 可以推送 no-cache 和 no-store 的资源;
- 一旦连接被关闭,Push Cache 就被释放;
- 多个页面可以使用同一个 HTTP/2 的连接,也就可以使用同一个 Push Cache。这主要还是依赖浏览器的实现而定,出于对性能的考虑,有的浏览器会对相同域名但不同的 tab 标签使用同一个 HTTP 连接;
- Push Cache 中的缓存只能被使用一次;
- 浏览器可以拒绝接受已经存在的资源推送;
- 你可以给其他域名推送资源。
🌙 9.HTTP2 和HTTP3的优缺点
http2优点:
多路复用:基于二进制数据帧和流, 解决TCP中队头阻塞的问题
头部压缩
🌙 服务端推送
http2缺点:
- TCP 以及 TCP+TLS建立连接的延时,HTTP/2使用TCP协议来传输的,而如果使用HTTPS的话,还需要使用TLS协议进行安全传输,而使用TLS也需要一个握手过程,在传输数据之前,导致我们需要花掉 3~4 个 RTT。
- TCP的队头阻塞并没有彻底解决。在HTTP/2中,多个请求是跑在一个TCP管道中的。但当HTTP/2出现丢包时,整个 TCP 都要开始等待重传,那么就会阻塞该TCP连接中的所有请求。
HTTP3:基于 UDP 协议的“QUIC”协议
- 实现了类似TCP的流量控制、传输可靠性的功能。虽然UDP不提供可靠性的传输,但QUIC在UDP的基础之上增加了一层来保证数据可靠性传输。它提供了数据包重传、拥塞控制以及其他一些TCP中存在的特性
- 实现了快速握手功能。由于QUIC是基于UDP的,所以QUIC可以实现使用0-RTT或者1-RTT来建立连接,这意味着QUIC可以用最快的速度来发送和接收数据。
- 集成了TLS加密功能。目前QUIC使用的是TLS1.3,相较于早期版本TLS1.3有更多的优点,其中最重要的一点是减少了握手所花费的RTT个数。
- 多路复用,彻底解决TCP中队头阻塞的问题
🌙 10.HTTP2 有没有可能比 HTTP1 还要更慢
🌙 11.var、let、const 的区别
🌙 12.说出打印结果
async function async1() {
console.log('async1 start');
await async2();
console.log('async1 end');
}
async function async2() {
console.log('async2 start');
}
console.log('script start');
setTimeout(function() {
console.log('setTimeout');
}, 0);
async1();
new Promise(function(resolve) {
console.log('promise1');
resolve();
}).then(function() {
console.log('promise2');
}).then(function() {
console.log('promise3');
});
console.log('script end');
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
打印结果:
script start
async1 start
async2 start
promise1
script end
async1 end
promise2
promise3
setTimeout
2
3
4
5
6
7
8
9
🌙 13.webpack常用plugins和loader
- 常用Plugin :
- clean-webpack-plugin:在打包之前将我们指定的文件夹清空。应用场景每次打包前将目录清空, 然后再存放新打包的内容, 避免新老混淆问题,非官方功能。使用说明 (opens new window)
- copy-webpack-plugin:打包相关的文档。除了JS/CSS/图片/字体图标等需要打包以外, 可能还有一些相关的文档也需要打包(word等)。文档内容是固定不变的, 我们只需要将对应的文件拷贝到打包目录中即可。使用说明。 (opens new window)
- mini-css-extract-plugin:是一个专门用于将打包的CSS内容提取到单独文件的插件。前面我们通过style-loader打包的CSS都是直接插入到head中的。使用说明 (opens new window)
- terser-webpack-plugin:压缩js代码
- optimize-css-assets-webpack-plugin:压缩css代码
- image-webpack-loader或img-loader:压缩图片。image-webpack-loader使用说明 (opens new window)、img-loader使用说明 (opens new window)
- postcss-sprites或webpack-spritesmith:合并图片。postcss-sprites使用说明 (opens new window)、 webpack-spritesmith使用说明 (opens new window)
- webpack-merge:用于优化配置文件。针对不同的环境将不同的配置写到不同的文件中。如:common文件做公共配置项文件,dev文件为开发配置,prod文件为上线配置。在dev,prod文件中配置webpack-merge,使其分别同common文件合并,并暴露给外界。
- SplitChunksPlugin:Code-Splitting实现的底层就是通过Split-Chunks-Plugin实现的,其作用就是代码分割。
- Provide-Plugin:功能同imports-loader,自动加载模块,所配置模块(jquery等)可以在全局使用。而不必在html头部引用,或在import导入模块。使用说明 (opens new window)
- IgnorePlugin:用于忽略第三方包指定目录,让指定目录不被打包进去。使用说明 (opens new window)
- add-asset-html-webpack-plugin:将打包好的库引入到html界面上
- DllPlugin:生成动态库的映射关系,即dll/[name].mainfest.json文件
- DllReferencePlugin:查找动态库。把只有 dll 的 bundle(们)(dll-only-bundle(s)) 引用到需要的预编译的依赖。
- webpack-bundle-analyzer:可视化的打包优化插件。会将打包的结果以图形化界面的方式展示给我们,并且在本地开启服务器,将服务器上生成的界面自动在浏览器中展示出来。使用说明 (opens new window)
- watch:webpack 可以监听打包文件变化,当它们修改后会重新编译打包
- webpack-dev-server: webpack-dev-server和watch一样可以监听文件变化,两者不要同时配置,防止冲突。 webpack-dev-server可以将我们打包好的程序运行在一个服务器环境下 webpack-dev-server可以解决企业开发中"开发阶段"的跨域问题 可以监听css,js代码且能自动刷新
- HMR(HotModuleReplacementPlugin):热更新插件, 会在内容发生改变的时候,时时的更新(打包)修改的内容但是不会重新刷新网站。推荐使用
- babel:将ES678高级语法转换为ES5低级语法,否则在低级版本浏览器中我们的程序无法正确执行。使用说明 (opens new window)
- babel-preset-env:告诉webpack我们需要兼容哪些浏览器,然后babel就会根据我们的配置自动调整转换方案, 如果需要兼容的浏览器已经实现了, 就不转换了。
- babel/polyfill:没有对应关系就是指E5中根本就没有对应的语法, 例如Promise, includes等方法是ES678新增的。ES5中根本就没有对应的实现, 这个时候就需要再增加一些额外配置, 让babel自己帮我们实现对应的语法。
- babel/parser:将JS代码转换为AST抽象语法树。使用说明 (opens new window)
- abel/generator:将AST抽象语法树转换为JS代码。
- babel/traverse:遍历抽象语法树。使用说明 (opens new window)
- babel/types:创建AST抽象语法树。使用说明 (opens new window)
- html-withimg-loader:实现HTML中图片的打包(file-loader或者url-loader并不能将HTML中用到的图片打包到指定目录中)。使用说明 (opens new window)
常用loader:
- file-loader:打包图片,打包字体图标。使用说明 (opens new window)
- url-loader 功能类似于 file-loader,但是在文件大小(单位 byte)低于指定的限制时,可以返回一个 DataURL(提升网页性能)。使用说明 (opens new window)
- css-loader:和图片一样webpack默认能不能处理CSS文件, 所以也需要借助loader将CSS文件转换为webpack能够处理的类型。解析css文件中的@import依赖关系,打包时会将依赖的代码复制过来代替@import。
- style-loader: 将css文件通过css-loader处理之后,将处理之后的内容插入到HTML的HEAD代码中。
- scss-loader:自动将scss转换为CSS
- less-loader:自动将less转换为CSS
- PostCSS-loader:PostCSS和sass/less不同, 它不是CSS预处理器(换个格式编写css)。PostCSS是一款使用插件去转换CSS的工具,PostCSS有许多非常好用的插件。例如:autoprefixer(自动补全浏览器前缀)、postcss-pxtorem(自动把px代为转换成rem)。使用说明 (opens new window),必须放在css规则的最后,最先执行。
- eslint-loader:用于检查常见的 JavaScript 代码错误,也可以进行"代码规范"检查,在企业开发中项目负责人会定制一套 ESLint 规则,然后应用到所编写的项目上,从而实现辅助编码规范的执行,有效控制项目代码的质量。在编译打包时如果语法有错或者有不符合规范的语法就会报错, 并且会提示相关错误信息。使用说明 (opens new window)
- imports-loader(不推荐使用):1. 自动加载模块功能同 Provide-Plugin,2. 还可修改全局this指向(一般都是使用此功能)。使用说明 (opens new window)。
- loader-utils:获取配置文件webpack.config.js文件中option传递的参数。
- schema-utils:校验配置文件传递的参数。
🌙 13.1 何为插件(Plugin)
Plugin 是一个扩展器,它丰富了 webpack 本身,针对是 loader 结束后,webpack 打包的整个过程,它并不直接操作文件,而是基于事件机制工作,会监听 webpack 打包过程中的某些节点,执行广泛的任务。
Plugin 的特点
- 是一个独立的模块
- 模块对外暴露一个 js 函数
- 函数的原型
(prototype)上定义了一个注入compiler对象的apply方法apply函数中需要有通过compiler对象挂载的webpack事件钩子,钩子的回调中能拿到当前编译的compilation对象,如果是异步编译插件的话可以拿到回调callback - 完成自定义子编译流程并处理
complition对象的内部数据 - 如果异步编译插件的话,数据处理完成后执行
callback回调。
实现一个自定义插件:
class DemoPlugin {
constructor(options) {
this.options = options
}
apply(compiler) {
// Tap into compilation hook which gives compilation as argument to the callback function
compiler.hooks.compilation.tap("DemoPlugin", compilation => {
// Now we can tap into various hooks available through compilation
compilation.hooks.optimize.tap("DemoPlugin", () => {
console.log('Assets are being optimized.')
})
})
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
🌙 13.2 何为loader
loader 用于对模块的源代码进行转换。loader 可以使你在 import 或"加载"模块时预处理文件。
loader特点: 单一原则, 一个loader只做一件事情 多个loader会按照从右至左, 从下至上的顺序执行
插件(plugin)是 webpack 的支柱功能。用于扩展webpack的功能。当然loader也是变相的扩展了webpack ,但是它只专注于转化文件这一个领域。而plugin的功能更加的丰富,而不仅局限于资源的加载。一个插件就是一个类,可以在打包过程中的特定阶段执行。 从作用角度简单来讲:loader帮助我们加载文件资源,而plugins则是loader的延伸,并不限制于加载文件资源。丰富了loader的功能。
const loaderUtils = require('loader-utils');
module.exports = function(source) {
// 获取到用户给当前 Loader 传入的 options
const options = loaderUtils.getOptions(this);
// 关闭该 Loader 的缓存功能
this.cacheable(false);
return source;
};
2
3
4
5
6
7
8
🌙 14.如果有一个工程打包特别大,如何进行优化?
1.首先排查打包环节,使用 webpack 插件 speed-measure-webpack-plugin (opens new window) 查看在打包中各个阶段的耗时;分析依赖打包情况可以使用:webpack-bundle-analyzer (opens new window);lighthouse、performance、coverage等分析其他资源
2.代码压缩,gzip压缩(compression-webpack-plugin )、css压缩(mini-css-extract-plugin) (opens new window)、js压缩(uglifyjs-webpack-plugin (opens new window)不支持es6,terser-webpack-plugin (opens new window)支持es6)、html压缩(html-webpack-plugin (opens new window));nginx压缩(利用 nginx 的 GZip Precompression 模块)、图片压缩(image-webpack-loader,可转为webp)
3.移除不必要的模块
4.选择可替代的体积较小的模块.比如: 使用day.js代替moment.js
5.按需引入模块,如:antd使用esm方式引入,便于tree shaking
6.code spliting 按需加载,优化页面首次加载体积
7.bundle spliting,在 webpack 中,使用
splitChunks.cacheGroupsmodule.exports = { //... optimization: { splitChunks: { chunks: 'async', minSize: 30000, maxSize: 0, minChunks: 1, maxAsyncRequests: 5, maxInitialRequests: 3, automaticNameDelimiter: '~', automaticNameMaxLength: 30, name: true, cacheGroups: { vendors: { test: /[\\/]node_modules[\\/]/, priority: -10 }, default: { minChunks: 2, priority: -20, reuseExistingChunk: true } } } } };1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
278.路由懒加载,react-loadable
9.使用
DLLPlugin动态链接库,通过生成配置文件和模块进行建立关联。比如打包react和react-dom需要很长时间,我们可以通过把这两个包提前打包好,使用的时候直接引入这个已经打包好的包就可以了。const webpack = require('webpack') const path = require('path') module.exports = { entry: { react: ['react', 'react-dom'] }, output: { library: 'react', filename: '[name].dll.js' }, plugins: [ new webpack.DllPlugin({ name: 'react', path: path.resolve(__dirname, 'dist/manifest.json') }) ] }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
1810.第三方库使用cdn,不打包
const AddAssetHtmlCdnWebpackPlugin = require('add-asset-html-cdn-webpack-plugin');
module.exports = {
externals: {
'query': '$'
},
plugins: [
new AddAssetHtmlCdnWebpackPlugin(true, {
'jquery': 'http://code.jquery.com/jquery-3.4.1.js'
})
]
};
2
3
4
5
6
7
8
9
10
11
🌙 15.用户信息存储的方式Cookie、Session、Token
🌙 16.React 性能优化的方式
- 使用React.Memo来缓存组件
- 使用useMemo缓存大量的计算
- 使用React.PureComponent , shouldComponentUpdate
- 避免使用内联对象: 使用内联对象时,react会在每次渲染时重新创建对此对象的引用,这会导致接收此对象的组件将其视为不同的对象,因此,该组件对于prop的浅层比较始终返回false,导致组件一直重新渲染。
- 避免使用匿名函数: 它们在每次渲染上都有不同的引用,类似于内联对象
- 延迟加载不是立即需要的组件,使用新的React.Lazy和React.Suspense
- 调整CSS而不是强制组件加载和卸载
- 使用React.Fragment避免添加额外的DOM
🌙 17. 实现一个防抖函数
1.要求初次执行的时候立刻执行
2.可以取消等待
function debounce(fn, wait=200, immediate=true) {
let timer = null;
let f = function(...args) {
timer && clearTimeout(timer);
if(immediate) {
let flag = !timer;
timer = setTimeout(() => {
timer = null;
}, wait);
flag && fn.apply(this, args);
} else {
timer = setTimeout(() => {
fn.apply(this, args);
timer = null;
}, wait);
}
};
f.cancel = function() {
clearTimeout(timer); // 停止定时器
timer = null; // 清除变量
}
return f;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
🌙 17.1 实现一个节流函数
1.实现leading和trailing
2.可以取消等待
// 简单实现-定时器版(trailing=true)
function throttle1(fn, wait) {
let timer = null;
return function(...args) {
if(!timer) {
timer = setTimeout(() => {
fn.apply(this, args);
timer = null;
}, wait)
}
}
}
// 简单实现-时间戳版(trailing=true)
function throttle2(fn, wait) {
let pre = +new Date(); // 如果要首次执行 pre=0
return function(...args) {
let now = +new Date();
if(now - pre > wait) {
fn.apply(this, args);
pre = +new Date();
}
}
}
// 终极版
function throttle(fn, wait, {leading = true, trailing = true} = {}) {
let timeout
let previous = 0
return function(...args) {
let now = new Date().getTime()
if (!previous && leading === false) previous = now
let remaining = wait - (now - previous)
if (remaining <= 0 || remaining > wait) {
if (timeout) {
clearTimeout(timeout)
timeout = null
}
previous = now
fn.apply(context, args)
} else if (!timeout && trailing !== false) {
// 如果有剩余时间但定时器不存在,且trailing不为false,则设置定时器
// trailing为false时等同于只使用时间戳来实现节流
timeout = setTimeout(() => {
previous = leading === false ? 0 : new Date().getTime()
timeout = null
fn.apply(this, args)
}, remaining)
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
🌙 18.说出以下代码的输出
<div id="box">
<button id="anchor">click</button>
</div>
2
3
var box = document.getElementById('box');
var anchor = document.getElementById('anchor');
document.body.addEventListener('click', function() {
console.log(1)
})
anchor.addEventListener('click', function() {
console.log(2)
})
box.addEventListener('click', function() {
console.log(3)
}, true); // 第二个参数默认为: false,表示回调函数发生在冒泡阶段,true-表示回调函数发生在捕获阶段
box.addEventListener('click', function() {
console.log(4)
})
// 结果: 3 2 4 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
🌙 19. let a = "abc",解释器在解释在这句话的过程中,内存发生的变化,比如内存放在哪里,申请了多大的内存
🌙 20.介绍一下 esm 和 cjs 的差异
- 使用方式不同;
- ESM输出的是
值的引用,而CJS输出的是值的拷贝; - CJS的输出是
运行时加载,而ESM是编译时输出接口; - CJS是
同步加载,ESM是异步加载;
🌙 21.介绍一下前端安全问题
- xss:转义、http only、csp
- csrf:token、referer检测、验证码、samesite
- 点击劫持
- iframe
- opener
- cdn劫持
- sql注入:输入过滤
🌙 22.假设有一个页面需要实现下拉无限滚动加载,如何实现和优化
🌙 23.实现如下这样的函数(函数柯里化)
实现如下这样的函数`f()`,要求调用深度不限。(考察点:对 JS 对象化的理解)
f(1).val === 1
f(1)(2).val === 3
f(1)(2)(3).val === 6
f(10)(100)(1000)(10000).val === 11110
f(a0)(a1)(a2)...(an).val === a0 + a1 + a2 +...+ an
2
3
4
5
6
function f(...args) {
function _f(..._args) {
return f.apply(null, [...args, ..._args]);
}
_f.val = args.reduce((a,b) => a+b);
return _f
}
2
3
4
5
6
7
8